
Agent Validation
You can rely on our Agent to deliver repeatable and recoverable results. We've done the research.
Reliability Exceeds Human Benchmarks
LLMs reliably assign the same predicted scores across independent runs at rates that exceed human benchmarks for the same type of task. These benchmarks are based on agreement across several hundred codes, at greater volume humans begin to perform worse. In contrast, LLMs can easily annotate thousands of records or conversations while maintaining agreement.
Validation: Repeatable
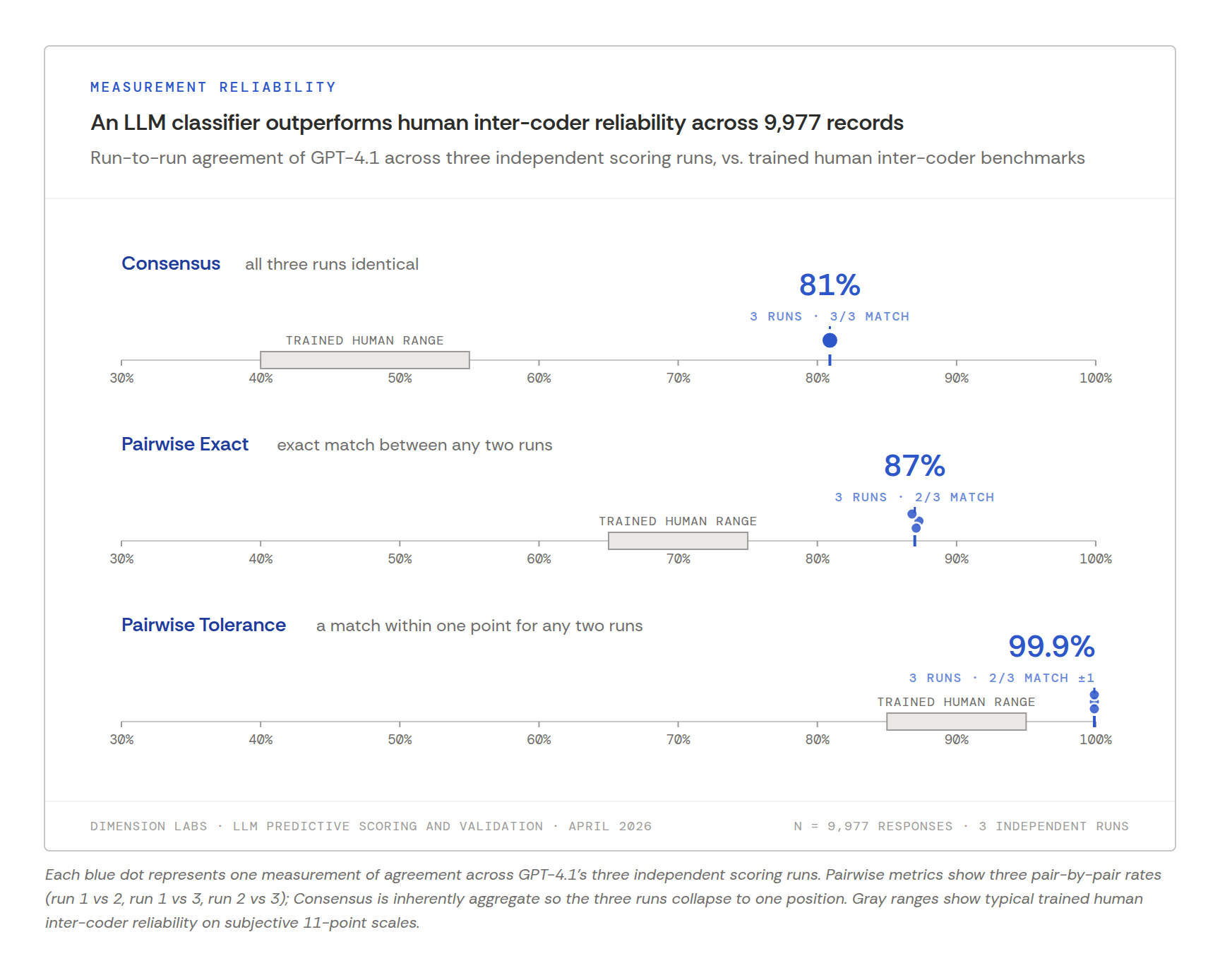
We published a validation study on 9,977 fan surveys from five MLB teams. GPT-4.1 read each open-text comment and predicted the 0–10 rating the fan had given on the same survey.
We ran the prompt three independent times against the same text. The prompt was deliberately plain: no examples, no calibration, and no domain-specific instructions.
The result was inter-labeler reliability scores that exceeded human benchmarks on all measures.
| Measure | Definition | AI | Benchmark |
|---|---|---|---|
| Consensus | All three runs identical | 80.9% | 40–55% |
| Pairwise Exact | Exact matches between any two runs | 87% | 65–75% |
| Pairwise Tolerance | A match within ±1 for any two runs | 99.9% | 85–95% |
Validation: Recoverable
We ran a validation study on 3,736 Givebutter support conversations that carried a customer-submitted satisfaction rating. GPT-4.1 read each conversation and predicted the 1–5 rating the customer had given, without ever seeing that rating.
Customer ratings are sparse. Of the ~70,260 support conversations in the window (November 2025–April 2026), only 3,736 carried a usable rating — fewer than 1 in 18. The predicted score is generated for every conversation, which is the point: it recovers a satisfaction signal for the ~95% of conversations that would otherwise have none.
The result was a predicted score that tracked customers' own ratings far more closely than tone-based sentiment, and reliably separated satisfied conversations from dissatisfied ones.
| Measure | Definition | AI | Sentiment baseline |
|---|---|---|---|
| Correlation | Agreement with the customer's own 1–5 rating (Pearson r) | 0.47 | 0.36 |
| Low-rating detection | Accuracy separating low (1–3) from high (4–5) ratings | 91% | 74% |
| Exact match | Predicted score equals the customer's rating | 66% | — |
| Within ±1 | Predicted score within one point of the customer's rating | 93% | — |
Ratings skew strongly positive: 91% are 4 or 5. Exact-match and within-±1 scores partly reflect that skew. The model's clear advantage over sentiment shows in correlation and low-rating detection, where the base rate offers no free lift.
Mechanics: Why LLM Annotation is Reliable and Precise
A reasonable question to ask of any LLM-powered system: how do we know the labels are accurate?
The short answer is that enrichment is a recognition task, not a generation task — and LLMs are dramatically more reliable at recognition than at generation.
| Task type | What it does | Hallucination risk |
|---|---|---|
| Generation | Write something new — an essay, a summary, a piece of code. | Higher. The model is producing content that didn't exist before. |
| Recognition | Identify whether a concept is present in existing text and label it. | Extremely low. The model is pattern-matching against text that's already there. |
When used for enrichment, LLMs deliver on:
- Consistency — no variation between human coders.
- Contextual understanding — capturing nuance and meaning, not just keywords.
- Reliability — extremely low hallucination rates on recognition tasks.
Validation studies confirm hallucination rates in enrichment tasks are extremely low. Pattern recognition and contextual understanding are exactly what large language models are best at.